Recently I’ve been working a lot with Qualtrics for a survey project. This post sums up a few thoughts about how you can make working with Qualtrics data a little bit easier for yourself. I’m pretty new to the survey and Qualtrics worlds, so I’m sure I’ll have missed useful shortcuts and the like. Feel free to let me know what I’ve missed out!
Get your data through the Qualtrics API
If you’re doing this in R, this is made relatively painless with the excellent qualtRics package. It’s possible to export the data from within Qualtrics. It’s not as risky as opening up the data in an Excel spreadsheet, but generally I think keeping the data at an arm’s length is a good idea. Besides, if you’re going to retrieve the data more than once, it’s way easier to build it into your data pipeline if you use the API.
Give informative names to your questions
By default, your questions are going to be given names like Q2.1 and these will also be the name of the variables when you retrieve the data i.e. these are not very informative variable names. To avoid that, simply edit the names in Qualtrics. We found the naming convention of block_question worked for us.
For example, say you’re running a survey about frozen desserts. Let’s say you have a question block about ice cream and a different question block about froyo. In each block you have two questions, one about whether the respondent prefers milk or dark chocolate and another about the respondent’s favorite fruit flavor. Then in the ice cream block you would title the first question icecream_choc and the second icecream_fruit.
Multiple responses within the same question
Sometimes a single question may actually nest multiple responses. For example, the question may be “Rate each of the following ice cream flavors on a scale of 1 to 5”, and then you present the respondent with three different flavors to rate: chocolate, vanilla, and strawberry. Let’s call this question flavors_rate.
What you will see in the data is three different variables, flavors_rate_1, flavors_rate_2,flavors_rate_3. You’ll notice these variable names aren’t very informative. We could just rename each of them “manually”, but if your survey is long enough that could be a lot of work and leaves a decent amount of room for error.1 Ideally, we’d like to find a way to automate this process as much as possible.
Here’s what I settled on. When you pull the data from Qualtrics, the variables will come with labels, which are additional text that provide more information about a variable. I’ve created an example dataset. First, I’ll print in the console and it looks like a normal dataframe.
library(tidyverse)
library(sjlabelled) # package to work with labels
df <- tibble(response_id = letters[1:3],
flavor_rate_1 = c(1, 2, 3),
flavor_rate_2 = c(2, 3, 4),
flavor_rate_3 = c(3, 4, 5))
df <- df %>%
mutate(flavor_rate_1 = set_label(flavor_rate_1, label = "chocolate"),
flavor_rate_2 = set_label(flavor_rate_2, label = "vanilla"),
flavor_rate_3 = set_label(flavor_rate_3, label = "strawberry"))
df %>%
gt::gt() %>%
gt::tab_header(title = "Survey responses with uninformative variable names")| Survey responses with uninformative variable names | |||
|---|---|---|---|
| response_id | flavor_rate_1 | flavor_rate_2 | flavor_rate_3 |
| a | 1 | 2 | 3 |
| b | 2 | 3 | 4 |
| c | 3 | 4 | 5 |
Now if you look at it with the View() function, you can see the text just below the variable names.
View(df)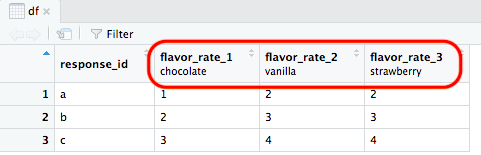
My suggestion is to extract the label (e.g. “chocolate”) and use it replace the numbers at the end of the variable names (e.g. flavor_rate_1 becomes flavor_rate_chocolate). I won’t walk through how to do this step-by-step but a couple of key steps are to (1) use the get_label function from the sjlabelled package and (2) use word from the stringr package to extract meaningful words from the labels.2 From there you can get a dataframe of variable names and labels and create new variable names through some string manipulation.
Below is some code to execute this idea:
label_shorten <- function(data, start = 1, end = start){
var_option_df <- data %>%
sjlabelled::get_label() %>%
enframe(name = "var", value = "option_long") %>%
mutate(option_long = str_squish(str_to_lower(option_long)),
option = word(option_long, start = start, end = end),
option = str_replace_all(option, "[^[:alnum:]]", ""),
option = str_squish(option))
var_option_df
}
replace_num_with_word <- function(vardf){
vardf %>%
tidyr::extract(var, into = c("var_prefix", "optionnum"),
regex = "(.+)_([0-9]{1,2})", remove = FALSE) %>%
mutate(newvar = str_c(var_prefix, option, sep = "_"))
}
labels <- label_shorten(df %>% select(-response_id))
labels = replace_num_with_word(labels)
gt::gt(labels %>% select(var, newvar)) %>%
gt::tab_header(title = "Dataframe of old and new variable names")| Dataframe of old and new variable names | |
|---|---|
| var | newvar |
| flavor_rate_1 | flavor_rate_chocolate |
| flavor_rate_2 | flavor_rate_vanilla |
| flavor_rate_3 | flavor_rate_strawberry |
df %>%
rename_at(labels$var, ~ labels$newvar) %>%
gt::gt() %>%
gt::tab_header(title = "Survey responses with informative variable names")| Survey responses with informative variable names | |||
|---|---|---|---|
| response_id | flavor_rate_chocolate | flavor_rate_vanilla | flavor_rate_strawberry |
| a | 1 | 2 | 3 |
| b | 2 | 3 | 4 |
| c | 3 | 4 | 5 |
You won’t always be able to automate this process. Maybe the options you provide are reasonably complex sentences, so it isn’t straightforward to extract a one-word descriptor from the label. In this case, after you construct the variable-label data frame (aka labels), you will still have to do some hard-coding, but it will be easier to do it in a transparent way.
For example, suppose you ask the question “Why didn’t you eat ice cream today?” and ask the respondent to choose from a number of different options: “I wasn’t hungry”; “The weather was too cold”; “I just had ice cream yesterday”. When the labels are in a dataframe, you can now write a series of conditions such as:
labels %>%
mutate(newvar_suffix = case_when(
str_detect(label, "hungry") ~ "nothungry",
str_detect(label, "too cold") ~ "toocold",
str_detect(label, "yesterday") ~ "ateyday"))Although this isn’t fully automated, it feels a bit safer to me since the renaming is reliant on the content of the question.
An added complication is that the numbering may not appear as you expect if the flavors are shifted around and/or added and removed as you edit the survey.↩
You could do something more sophisticated certainly, but
wordwill probably be good enough for 80% of cases, and the added complexity may not be worth it.↩